既存プロダクトに機械学習の推論APIを組み込む
お仕事で「既存プロダクトのデータを機械学習でフィルタリングして、その推論結果を記録する」機会があったので、そのときに考えたことや取った戦略について書いてみます。
やりたいこと
プロダクトのサーバー構成は下のような構成です。プロダクトAPIがRedisに対してデータの読み書きを行い、クライアント側に返すという構成です。
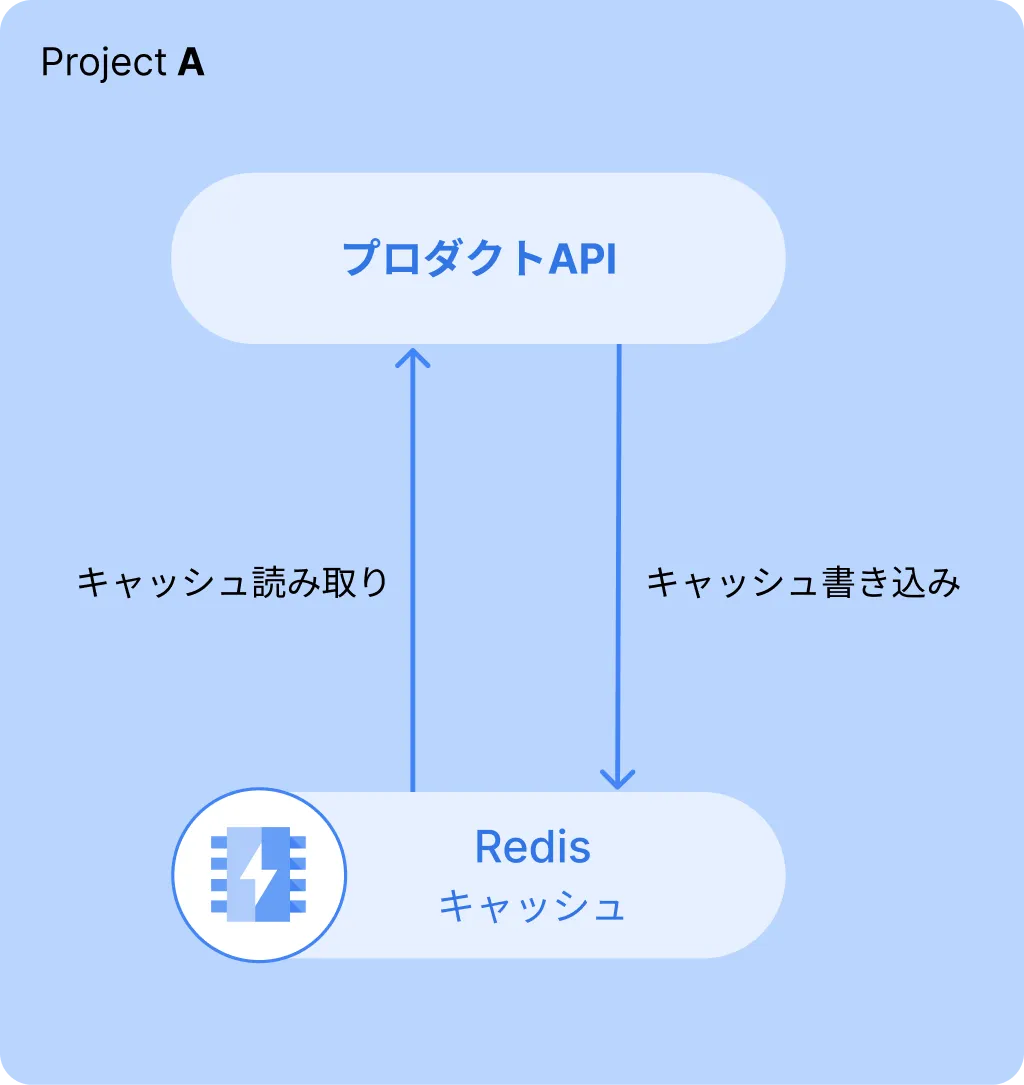
今回自分が達成したかったことは、このプロダクトAPIからデータを受け取り、機械学習で不要なデータを一部削除して、その結果をRedisに書き込む、ということです。
インフラ設計
最初の設計は下の画像のようなものを考えました。
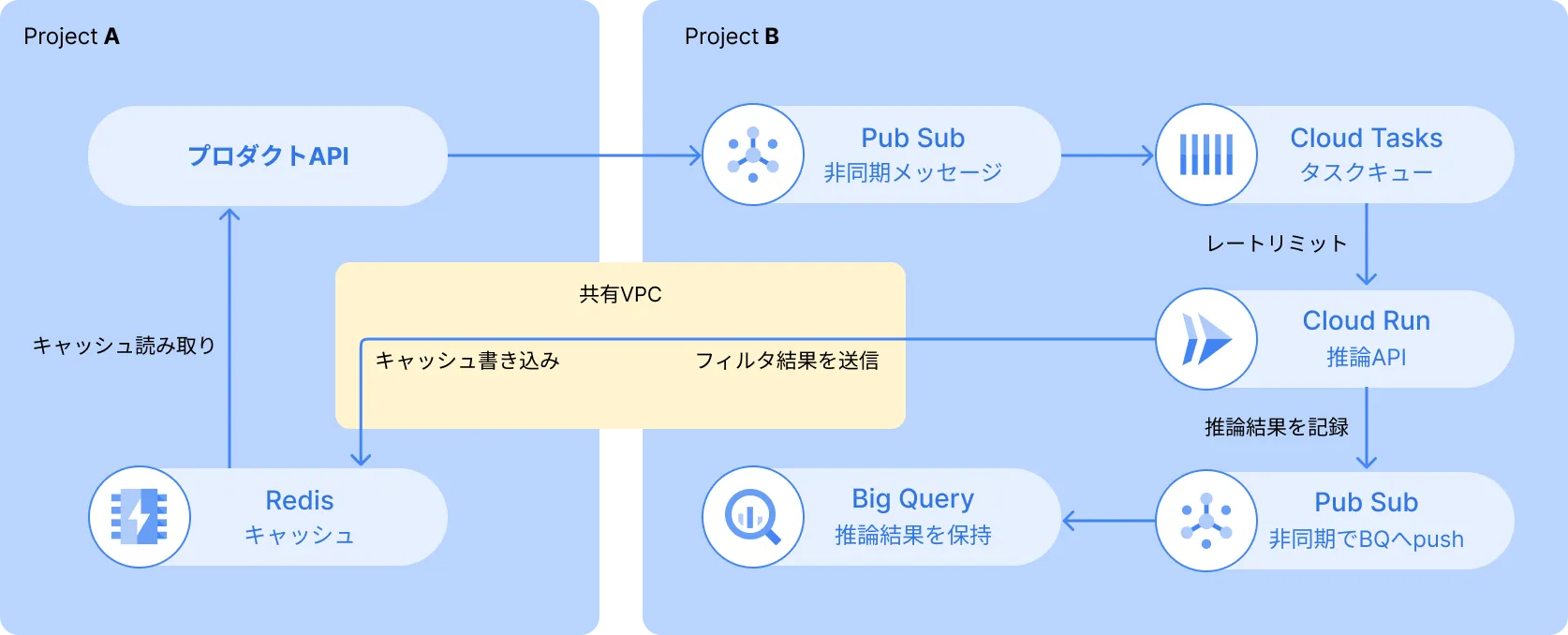
今回の機械学習モデルは、1回の推論で 100 ms ~ 1500 ms かかります。 プロダクトAPIのレイテンシを悪化させないように、非同期で推論を行いたいです。 そこで、Pub/Subを挟んで別のワーカーとしてCloud Runで推論を行うことにしました。
また、Pub/Subの後にCloud Tasksを入れることで、Cloud Runのインスタンス数が必要以上に増えないようにレートリミットを行います。
推論した結果はBigQueryにためておくことで、推論の精度評価や、後からの分析に使えるようにしました。Pub/SubのBigQuery Subscriptionを使うと、簡単にBigQueryへの非同期な書き込みが行えます。
設計の問題点
この設計は要件を満たすことはできるものの、機械学習の結果を直接Redisに書き込む部分に違和感がありました。例えば、
- プロダクトAPIが推論結果を別の場所に対して読み書きしたくなった場合
- Redisへのアクセス経路が1つから複数になってしまう
といったあたりです。
さらに今回、Google CloudのプロジェクトをプロダクトAPIのものとは別にしていたので、これを実現するにはVPCを共有した上で、Direct VPC Egressで書き込む必要もあります。
設計をブラッシュアップ
再考した結果、「推論サーバーから直接Redisに書き込む」という設計ではなく、むしろ「推論サーバーからは、Redisの存在を隠す」という方針を取ることに決めました。 というのも、推論サーバーの責務は「データを受け取り、不要なデータを推論で取り除く」だけであり、そのデータをどのように保持しておくかは、プロダクトAPIの責務だからです。
ということで以下のように、プロダクトAPIに新たなエンドポイントを作り、推論APIはそこに推論結果を投げるように変更しました。
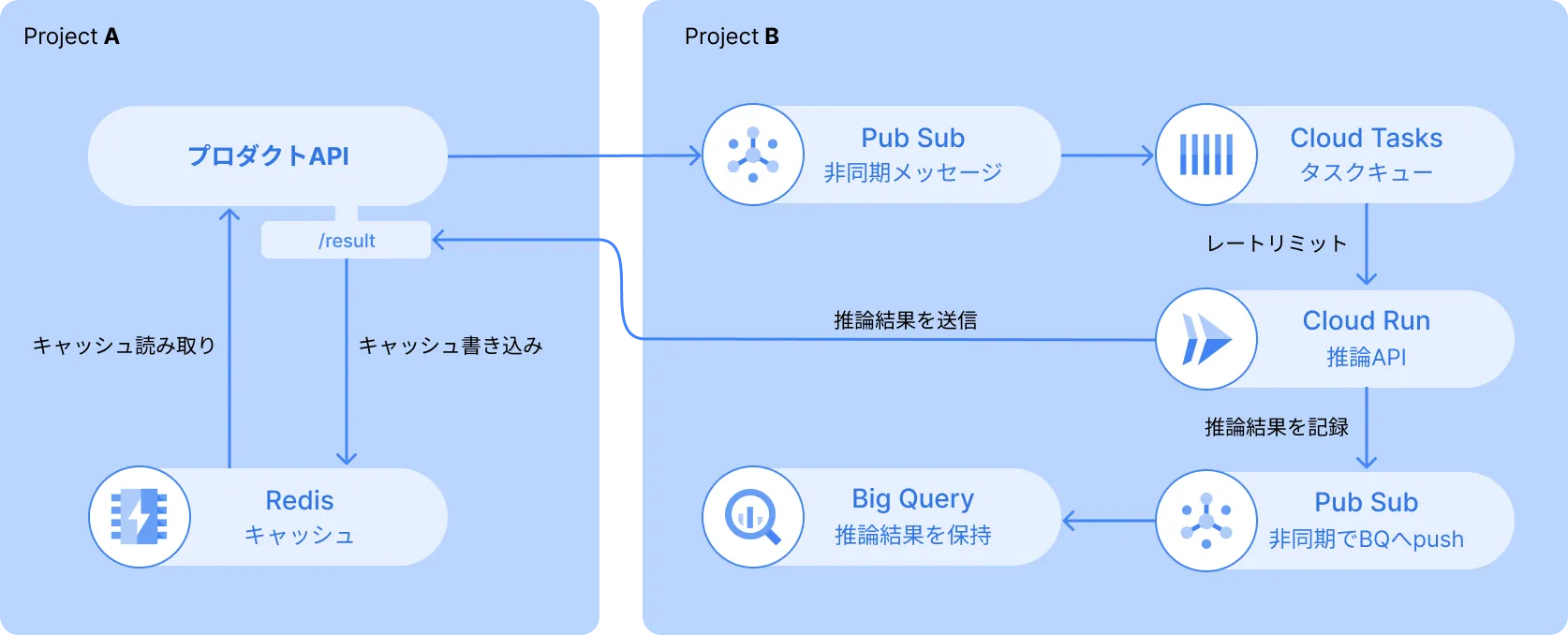
こうすることで、プロダクトAPIは受け取った推論結果をRedisに保存したり、RDBに保存したり、はたまた別の処理に使い回したりと、自由度が高まりますね。推論APIの方も、ひたすら推論に集中して、結果は指定のエンドポイントに投げるだけです。
ある種、インフラレベルでコールバックを行うような設計になりました。
推論サーバーについて
推論APIはFastAPIで作っています。
機械学習モデル
機械学習のモデル自体は、LINEヤフーが提供しているclip-japanese-baseというモデルをそのまま利用しています。日本語のデータセットで学習されており、言語と画像を同じ空間のベクトルに落とし込むことができます。
ただ、一般的に機械学習のモデル(重み)はサイズが大きいため、Dockerイメージには入れられません。 そこで、GCSバケットをCloud Runのファイルシステムにマウントできる機能を利用して、APIのスタートアップのタイミングでモデルを読み込むようにしています。
Cloud Runのリソースを効率的に使う
推論APIの中では、機械学習モデルのインスタンス(オブジェクト)を1つだけ生成して使うことで、メモリ使用量を抑えています。 リクエストの増加に対しては、Cloud Runの自動スケーリングで対応させつつ、リクエストが少ないときは最低限のリソース使用になるので、コストを削ることができます。
適切なCPU数・メモリ量や最大インスタンス数などは、負荷テストで目標値との兼ね合いを見ながら決めました。Locustを利用すると簡単に負荷テストを行えます。今回はCloud TasksがCloud Runを呼び出すので、実際の環境に近づけるために、GCEのインスタンスから負荷をかけました。
Pub Sub + Cloud Tasks で非同期処理とレートリミットを実現する
プロダクトAPIから推論APIへのメッセージングはPub/Subを使って非同期に行います。
また、負荷テストの結果から推論APIの最大スループットがわかっていました。それ以上のリクエストを送ってもレイテンシが遅くなるし、無駄にスケールアウトしてしまうとコストがかかり続けるので、Cloud Tasksでレートリミットをかけました。
今回、Cloud TasksのBufferTask APIを利用しました。この機能は、BufferTask APIのエンドポイントにHTTPリクエストを送るだけで、指定したエンドポイントにバッファリングしながらリクエストを送ってくれるというものです。クライアントライブラリで明示的にタスクを作成する必要がなくなるので、依存が少なくなります。 以下の記事が参考になりますので、気になる方はご覧ください。